
Documento técnico con los resultados preliminares de la línea de investigación orientada a monitorear la presencia de café de sombra; e inclusive evidencia de posible afectación por Roya.
Introducción
El café es un producto de importancia mundial y forma una fracción significativa de la economía de exportación de varios países (Chanakya y De Alwis, 2004). En México es un gran generador de divisas al cultivarse en 14 estados con más de 717 mil hectáreas, lo que lo vuelve un impulsor de la economía regional y sustento para más de medio millón de familias. De estos es Chiapas el principal productor y en particular, la Sierra Madre de Chiapas, la cual tiene una historia de producción cafetalera de casi 200 años, dando granos de alta calidad resultantes principalmente de sistemas agroforestales bajo sombra (Libert y Paz, 2017).
El cultivo bajo sombra o mediante sistemas tradicionales promueve la conservación de la biodiversidad al favorecer la conservación de especies y de numerosos servicios ambientales, ya que generalmente crece en un gradiente de elevación que representa zonas clave de transición biológica (Ortega-Huerta et al., 2012). Pero desde 2013 ésta ha presentado grandes pérdidas tanto en cantidad como en calidad debido a la epidemia de la roya, lo que ha desencadenado deforestación y degradación ambiental al promover variedades de café resistentes a la roya que no son compatibles con el manejo de sistemas agroforestales bajo sombra o el cambio de cultivo a maíz o pastizal para ganadería, poniendo en riesgo el sustento de miles de familias campesinas y los servicios ecosistémicos que este tipo de sistemas proveen (Libert y Paz, 2017).Relevancia de la línea de investigación
Debido a su importancia y a las afectaciones que está presentando por la roya, es importante generar mecanismos que permitan llevar a cabo un monitoreo de su estado. Normalmente éste se realiza mediante visitas en campo, lo que conlleva altos costos en tiempo y dinero. Por lo tanto, deben plantearse metodologías que permitan tanto la identificación del cultivo como de la roya y que reduzcan la inversión monetaria y temporal. En este sentido la percepción remota ha sido ampliamente usada para el monitoreo de vegetación, aunque los métodos comúnmente usados han mostrado bajas confiabilidades al intentar discriminar coberturas compuestas por diferentes especies como es el caso del café, por lo tanto en los último años se ha probado la efectividad de los datos hiperespectrales para la detección de especies que se encuentran mezcladas con otras. Tal es el caso del presente informe, donde se presentan los resultados obtenidos del uso de diferentes métodos de percepción remota para la identificación del cultivo así como de la obtención de información híperespectral del cultivo de café en ausencia y presencia de la roya y de otros componentes de la cobertura forestal en que se desarrolla, para brindar conocimiento sobre la efectividad que los datos hiperespectrales pueden tener para la identificación del cultivo y de la roya y así ayudar a la construcción de un sistema de monitoreo basado en imágenes satelitales y el uso de drones.
Métodos
El área de estudio se limitó al estado de Chiapas debido a que sólo fue posible obtener información sobre dicho estado y a que es el mayor productor cafetalero del país. La información base utilizada para calibrar los algoritmos de percepción remota se generó a partir del Inventario Nacional Forestal y de Suelos 2009-20014 (INFyS) el cual se encuentra libre en línea
Debido a que las bases de datos no cuentan con un campo llave, fue necesario generarlo para poder relacionarlas y así obtener el tipo de vegetación por conglomerado (Tabla Arbolado) y los conglomerados que tenían café (Tabla Diversidad_especie_estrato), los cuales fueron empleados para crear los campos de entrenamiento y de verificación (Anexo 1), los primeros se emplearon para correr el clasificador de Máxima Verosimilitud (Anexo 2) y los segundos para medir la confiabilidad de todos los resultados. Otro método supervisado que se probó fue el demezclado espectral lineal de ENVI (Anexo 3), el cual requiere firmas espectrales de los elementos más representativos de la imagen para poder obtener imágenes de las fracciones de cobertura de cada uno de estos. Aunque lo recomendable es emplear firmas del dosel, ya que la identificación se haría a nivel del copa, esto no fue posible pues la imagen tomada por el dron se dañó en las bandas azul, verde y rojo, por lo que se decidió usar la biblioteca espectral obtenida en campo con un espectrorradiómetro a nivel de hoja (Anexo 4). También se corrió extrayendo los endmembers directo de la imagen utilizando los campos de entrenamiento como semillas. Debido a la falta de endmembers para correr el demezclado espectral supervisado, se decidió correr uno no supervisado denominado SMACC (The Sequential Maximum Angle Convex Cone) el cual se encuentra disponible en ENVI, esto con la finalidad de poder identificar aquellos elementos que eran más abundantes en la imagen (Anexo5). Por último, con las imágenes de abundancia derivadas de los demezclados espectrales lineales supervisado, se generaron árboles de decisión para crear clasificaciones que permitieran identificar el cultivo del café.
Resultados preliminares
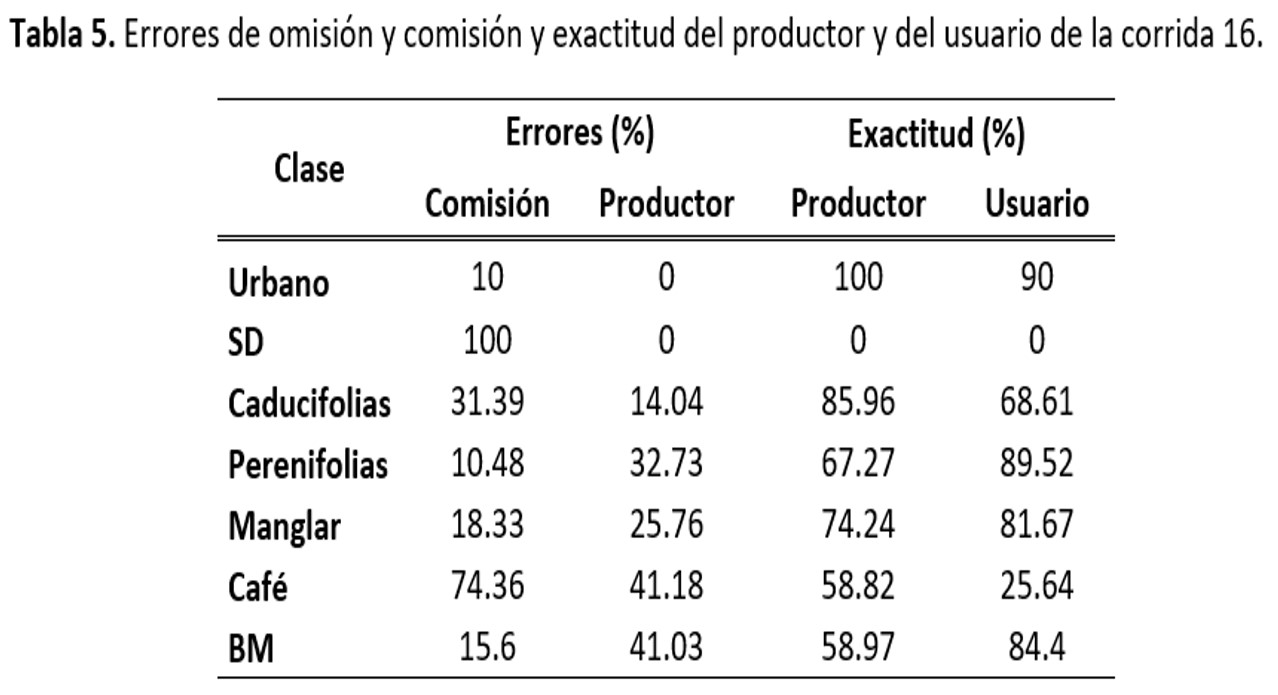
De las clasificaciones obtenidas de realizar el clasificador máxima verosimilitud se encontró que conforme se iba reduciendo el número de clases, tanto la confiabilidad como el índice Kappa iban incrementándose, siendo las que arrojaron una mayor exactitud global las que se corrieron con 7 clases y sin índice de vegetación (corrida 13) y con el SAVI (corrida 16; 72.9% y 72.6%, respectivamente). El hecho de que hayan mostrado un índice Kappa de 0.66 y 0.65 indica que los resultados no son explicados por el azar por lo que son confiables. Cabe resaltar que al quitar la clase Agropecuario, ambos valores aumentan hasta sobrepasar el 70% y el 0.65, respectivamente (Tabla 1).
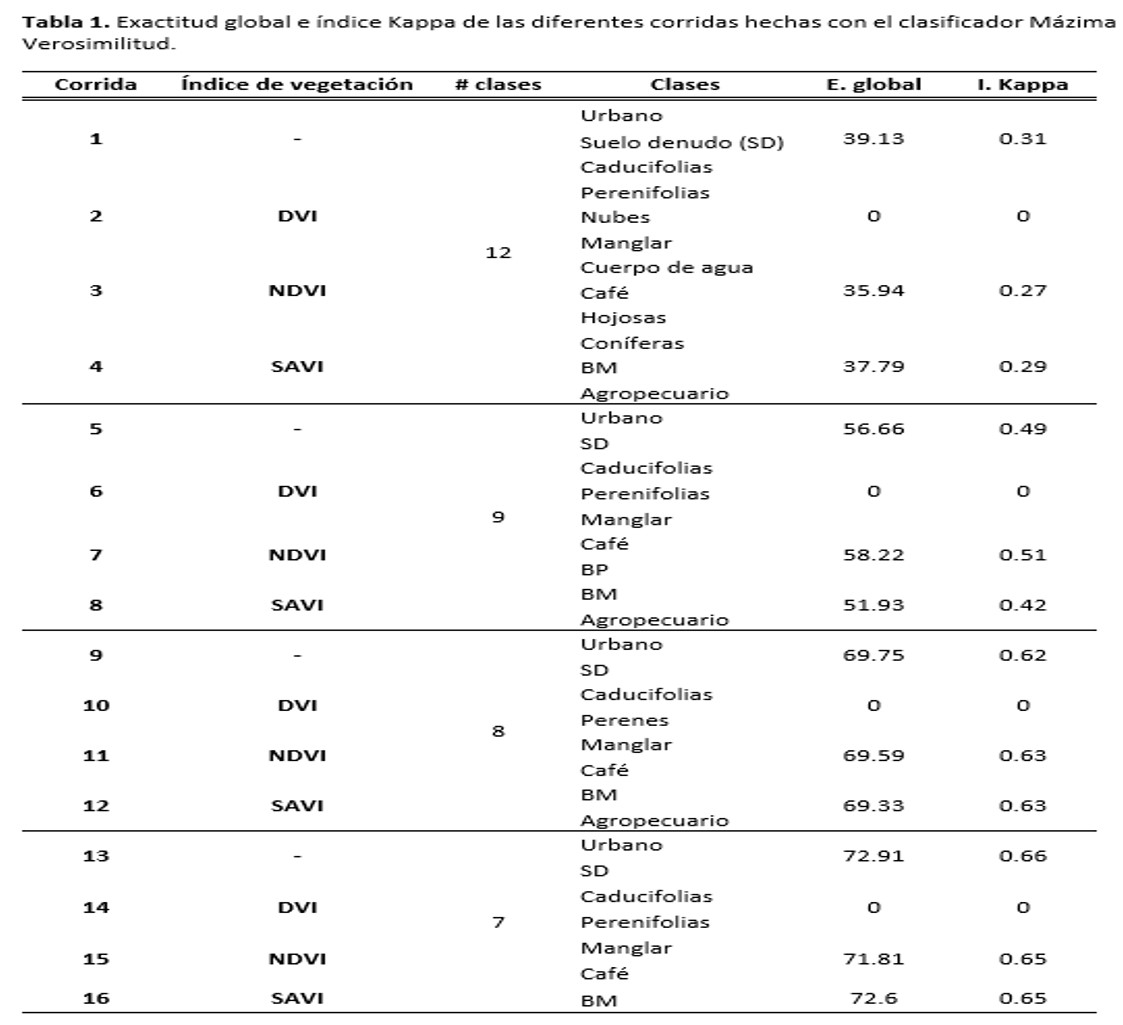
De las dos corridas que muestran el mejor resultado, es la 13 la que tiene menor confusión en la clase de café, alcanzando un 61.8% de concordancia y una exactitud del usuario de 61.8% (Tablas 2 y 3). La corrida 16 por su parte, presenta una exactitud del productor de 58.82. En ambos casos esta clase tiene mayor confusión con Caducifolias (arriba del 20%) y en menor mediad con Perenifolias y Bosque Mesófilo (por debajo del 9%). El que la reducción de clases haya arrojado mayores confiabilidades era de esperarse pues esto disminuye confusiones que se pueden dar entre clases con reflectividad semejante como es el caso de urbano, suelo desnudo y nubes. Así mismo se esperaba que la presencia de Agropecuario no afectara en la confiabilidad de café pues en el estudio deCordero-Sancho y Sader (2007) reportan confiabilidades arriba del 80% usando Landsat (ETM+), un clasificador supervisado, diferentes capas de información para identificar el cultivo de café y considerando la presencia de cultivos.
A pesar de que las clasificaciones antes mencionadas arrojaron confiabilidades arriba del 70% ésta sigue siendo baja en el caso de café pues analizando las exactitudes del usuario éstas son bajas, alrededor del 25%, lo que las hace poco adecuadas para ser empleadas con fines de consulta o uso para la ubicación del cultivo. Esta baja exactitud se debe principalmente a la alta confusión que presenta con la cobertura de bosque mesófilo, lo cual era altamente probable que sucediera, pues este tipo de bosque es común que se use como sombra para el café. Lo que es menos probable encontrar es la confusión que se observó de café con vegetación caducifolia, pues son zonas cuyas condiciones no son las más adecuadas para el café, pero sin embargo, se reporta la presencia de este cultivo en este tipo de vegetación.
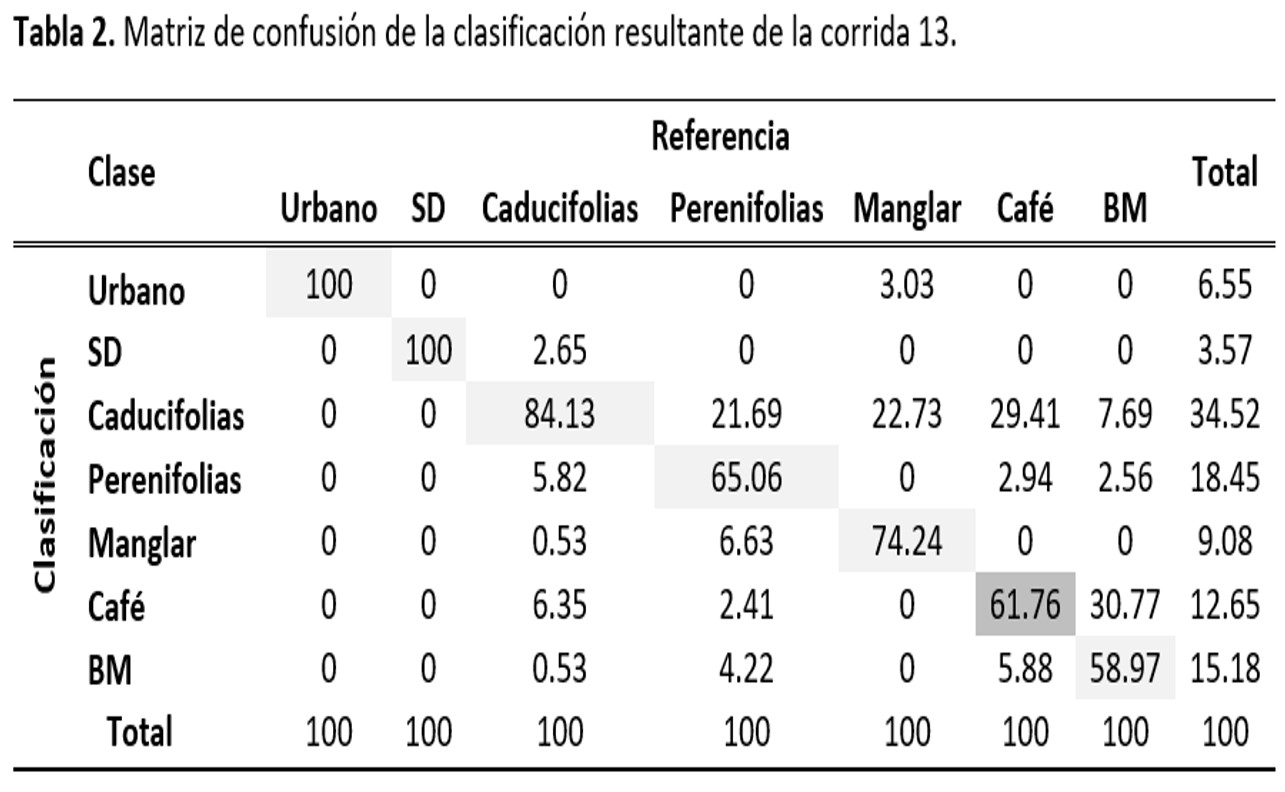
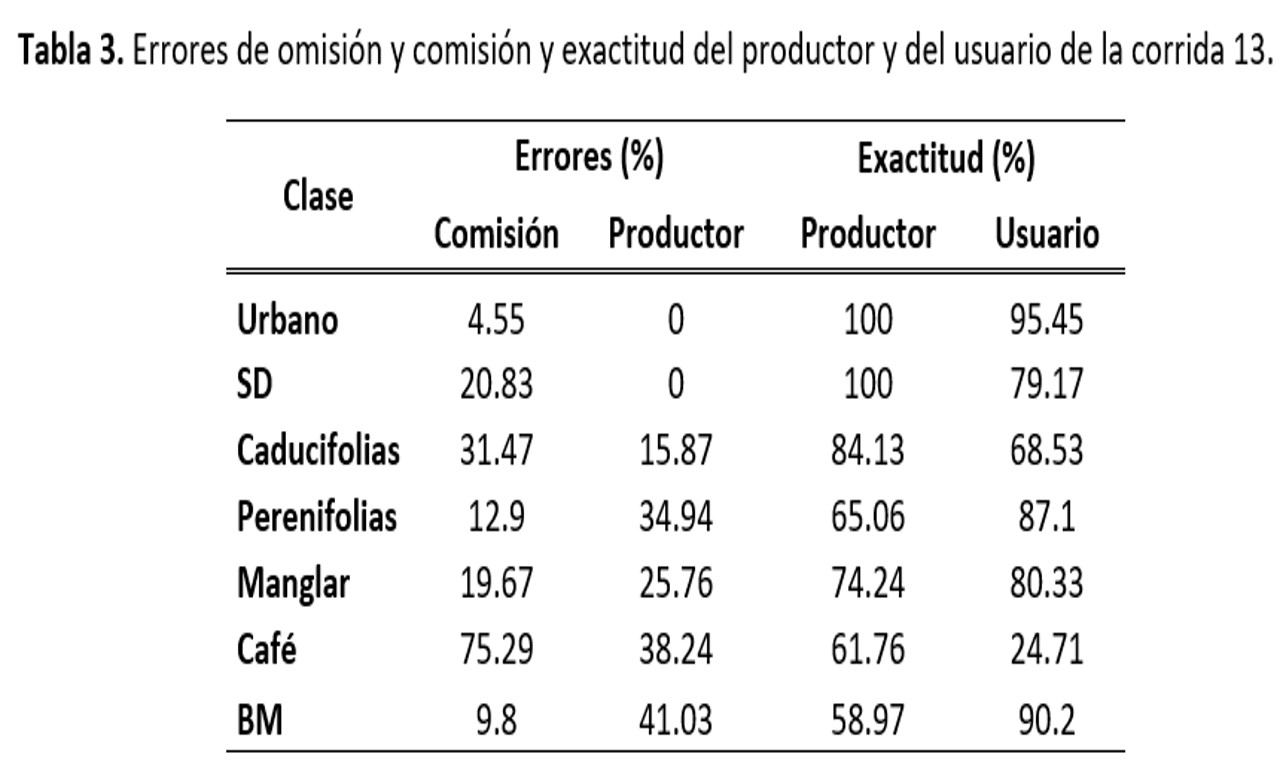
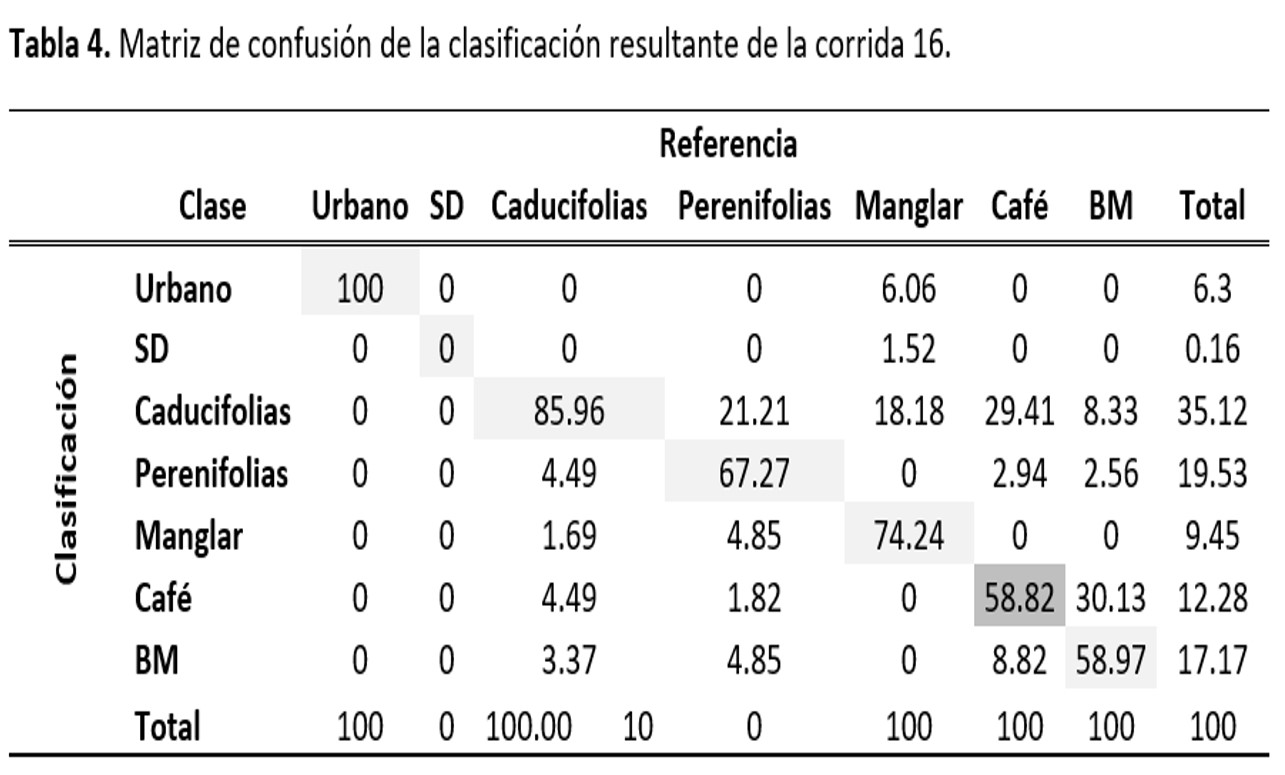
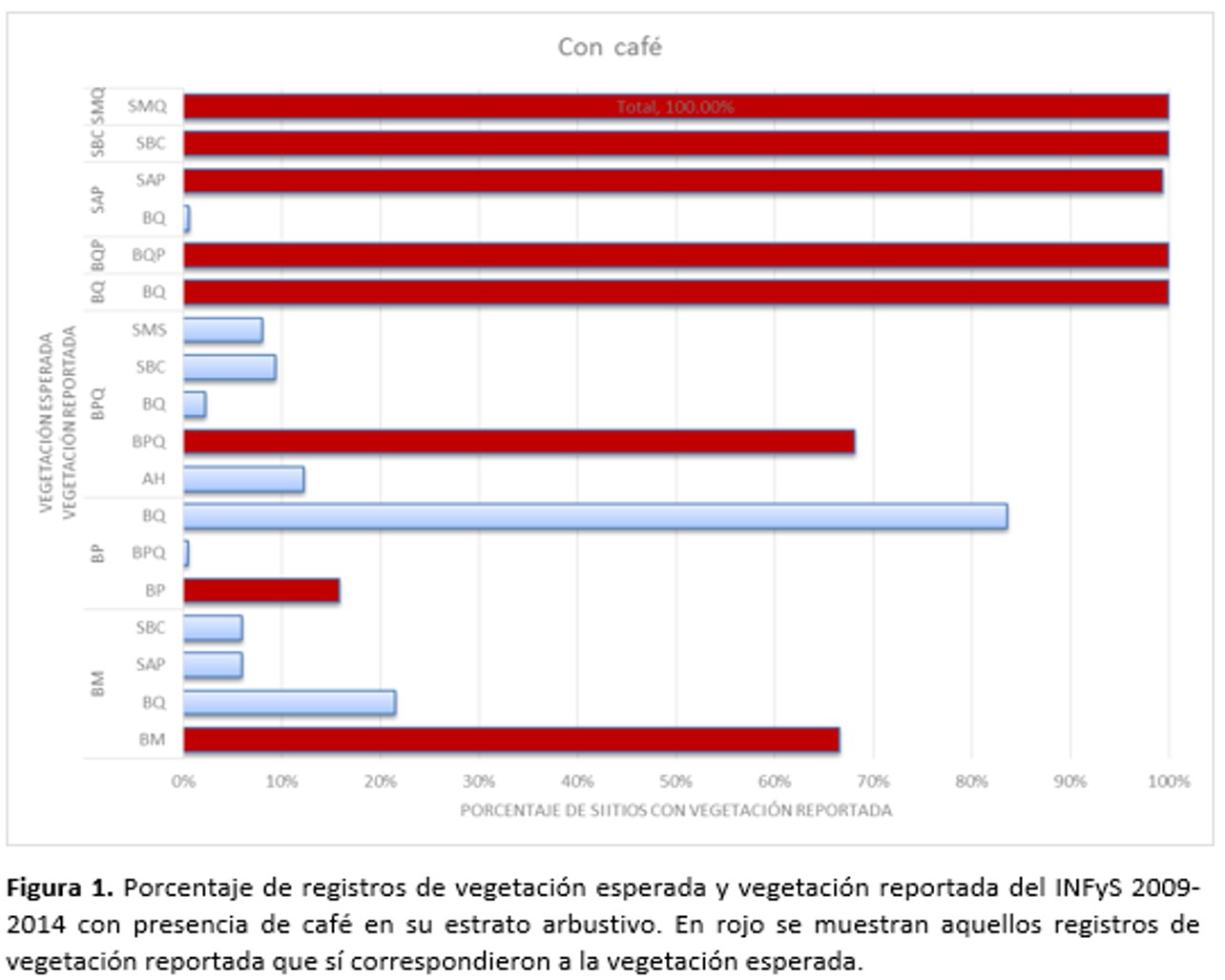
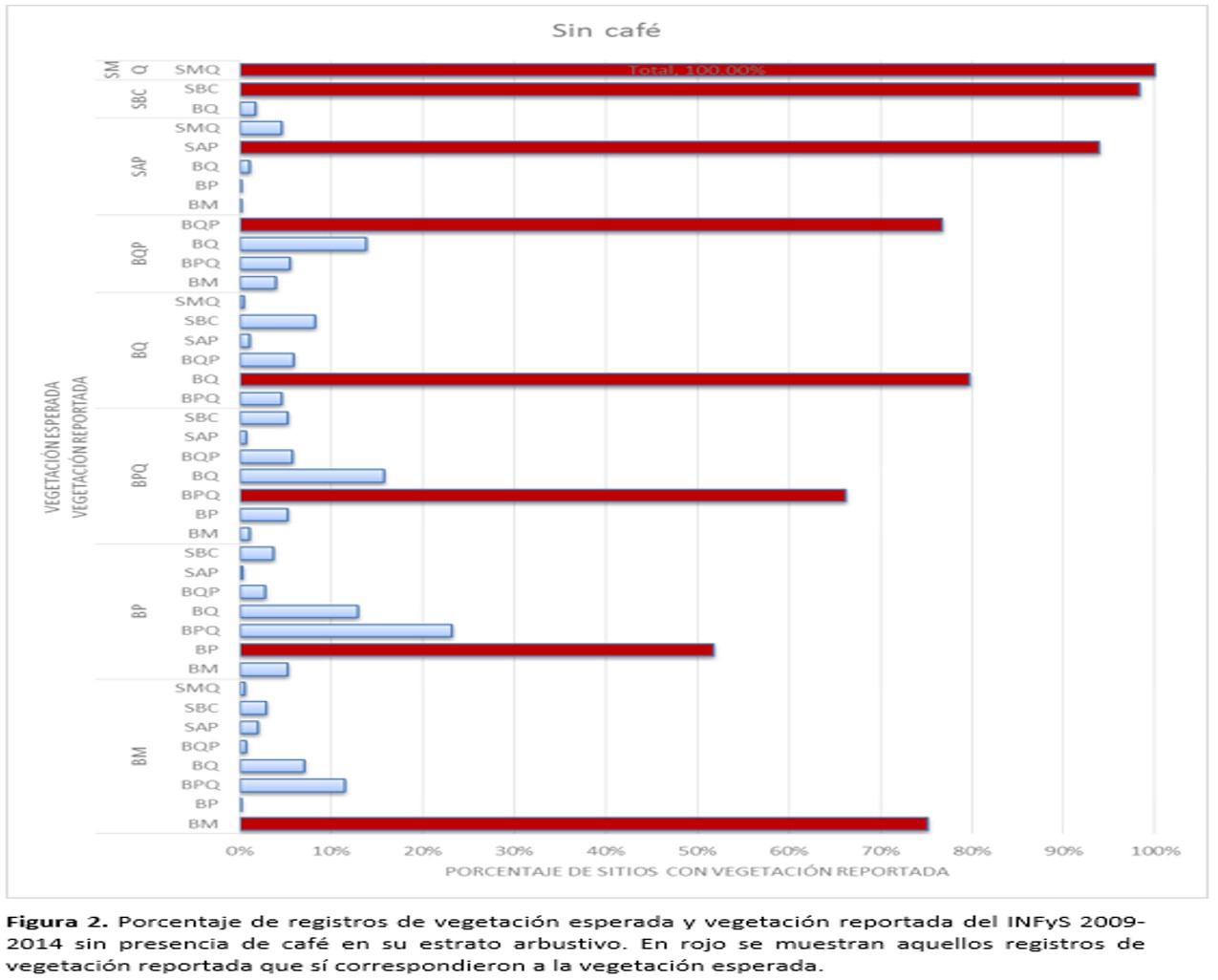
Otro punto importante a considerar para explicar las bajas confiabilidades obtenidas por la clasificación supervisada, es el origen de los datos semilla y de verificación, ya que a pesar de que se crearon a partir del INFyS 2009-2014, éste sólo contaba con 44 conglomerados con café como especie del estrato herbáceo, teniendo entre 5 y 8 conglomerados (de 400m2 cada uno) por imagen. Es decir, en realidad se tenían alrededor de tres conglomerados para calibrar y otros tres para verificar, lo que no es suficiente para obtener una clasificación con una exactitud significativa, pues Jensen (2005) y McCoy (2005) recomiendan que el número de pixeles que se deben de considerar para formar los campos de entrenamiento y verificación por clase debe ser 10 veces el total de bandas y en este caso no se pudo conseguir ese número de muestras. Además, al no contar con información sobre porcentaje de cobertura, no es posible determinar si estos conglomerados tenían un porcentaje significativo de café dentro de la parcela para que pudiera ser medido por el satélite. Por último, varios de estos conglomerados reportaban un tipo diferente de vegetación al esperado, lo que puede deberse tanto a un error en la clasificación de la serie III y IV del INEGI o porque la tipificación de la vegetación no se está haciendo correctamente, por lo que es probable que las semillas empleadas no están representando el tipo de vegetación que se supondría deberían de tener. Como ejemplo se puede mencionar el bosque mesófilo del cual más del 20% de las muestras que estaban previamente catalogadas con este tipo de vegetación, se reportan como bosque de Quercus sp. De acuerdo con Rzedowski (2006) el bosque mesófilo puede estar compuesto por diversas especies arbóreas, entre ellas encinos (Quercus sp.), por lo que es posible llegar a confundirlo con un encinar y más si la identificación de la cobertura no se hace con cuidado y sin considerar la presencia de especies indicadoras de mesófilo (Figura 1 y 2).
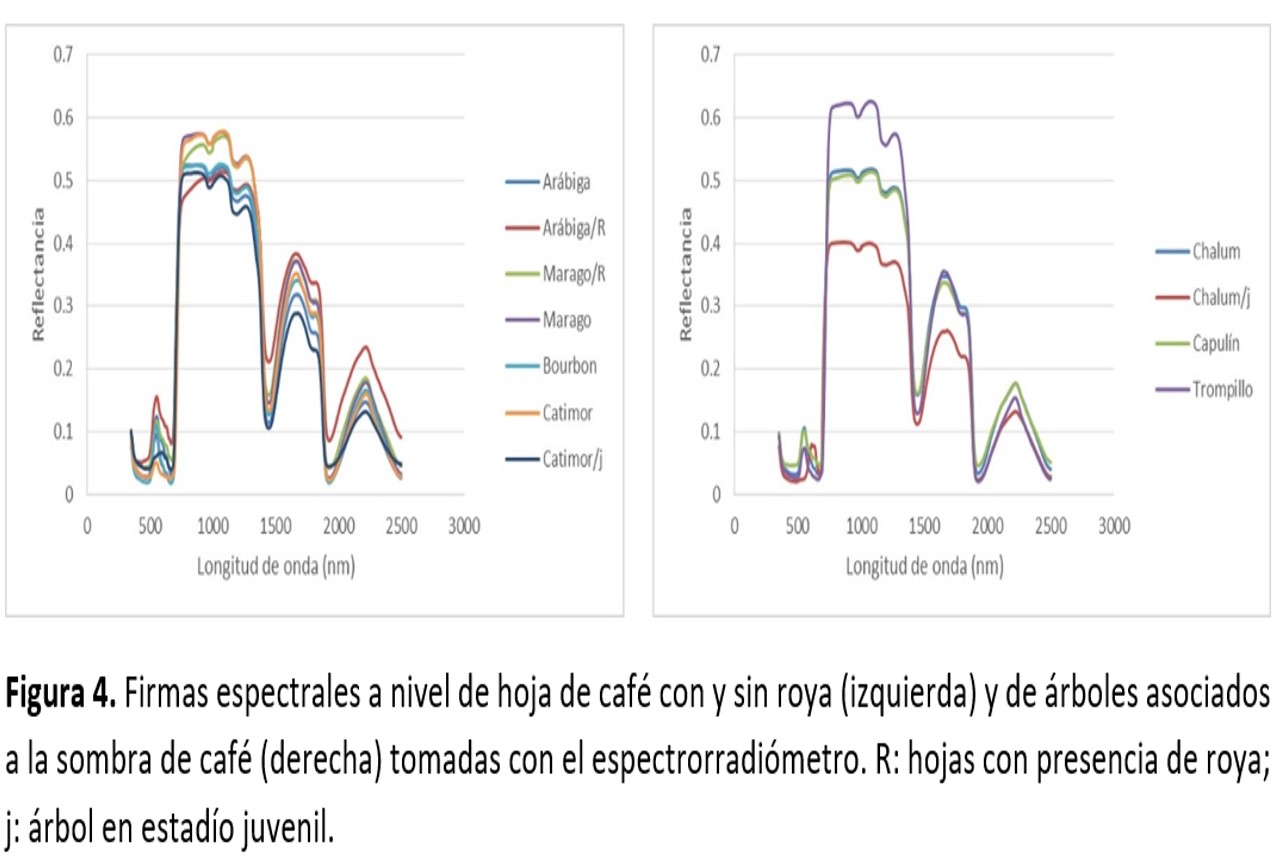
Con respecto al Demezclado espectral lineal el que se corrió utilizando los datos de entrenamiento para extraer los endmembers no arrojó buenos resultados, ya que se espera que el valor máximo que pueda presentar un pixel sea igual o menor a 1 y en este caso se identificaron valores por debajo del cero y por encima de la unidad, llegando hasta 200. Sólo el resultante de aplicar los endmembers recolectados del espectrorradiómetro y remuestreados a la resolución espectral de Landsat 8 arrojaron resultados acordes a lo esperado (Abundancias entre 0.4 y 0.6 del endmember de vegetación asociada a sombra de café), aunque también presentaron valores por encima de la unidad y negativos (Tabla 6). Esto seguramente se deba a que algunos de los endmembers empleados (Coníferas, bosque mixto y suelo desnudo) eran a nivel del dosel y no de hoja, por lo que los endmembers tomados de la hoja mostraron reflectancias casi del doble de los antes mencionados (Figura 3).
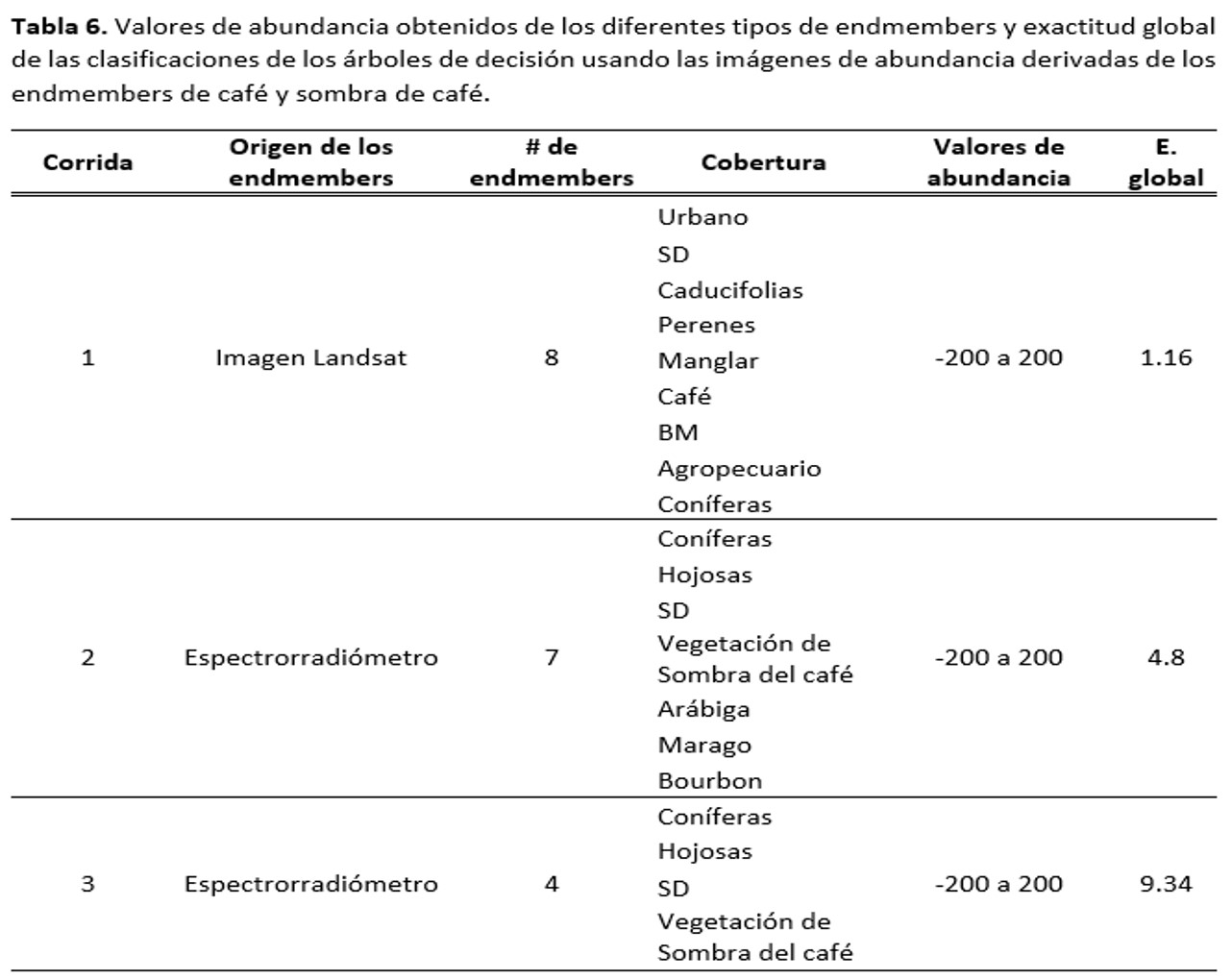
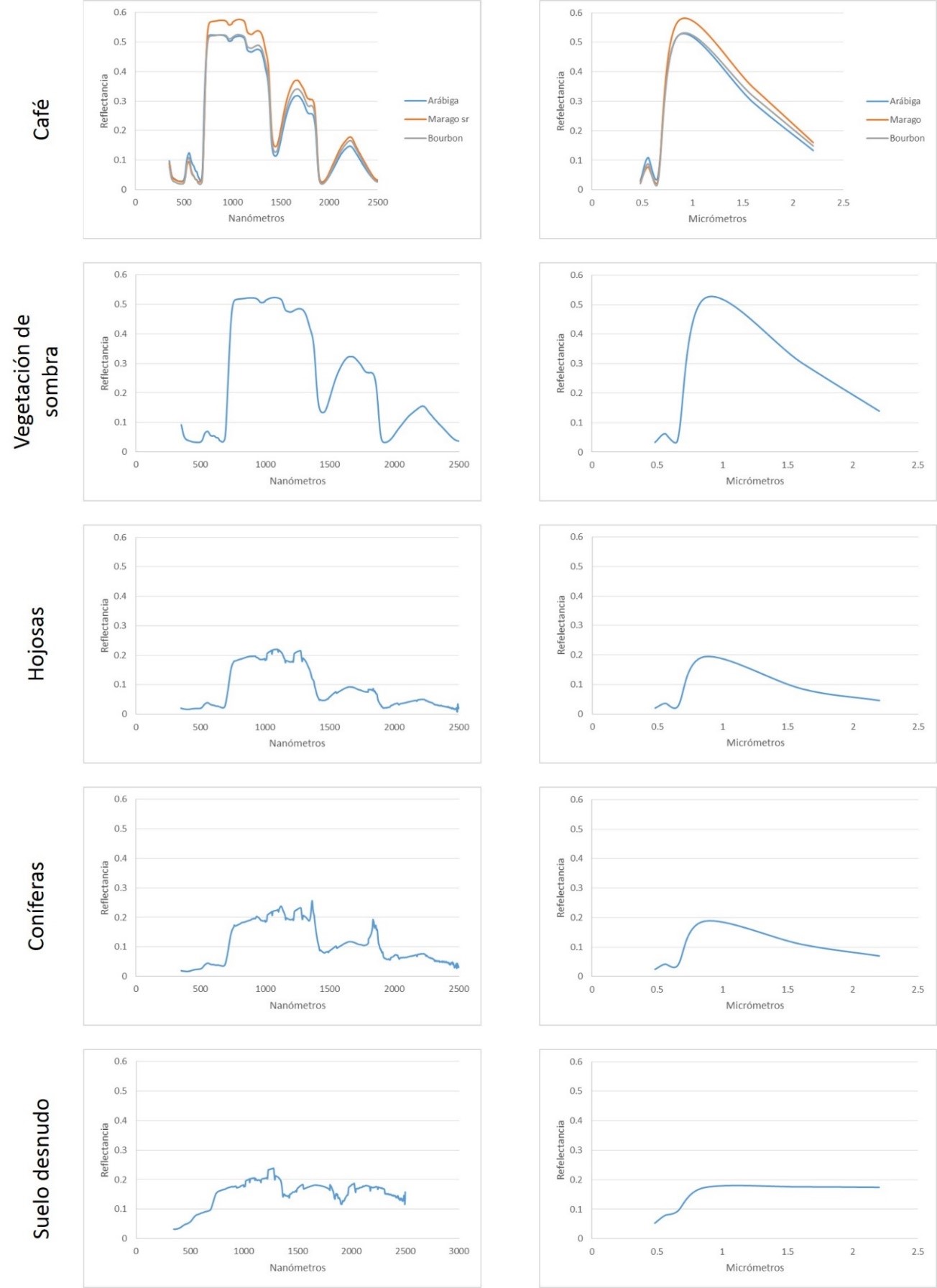 De los diferentes árboles de decisión que se corrieron a partir de las imágenes de abundancia de los demezclados espectrales generados, se encontró que ninguno de ellos muestra exactitudes confiables, por lo que es necesario considerar otros endmembers que mejoren los resultados de las clasificaciones, ya que sí hubo una mejora en el método al utilizar endmembers tomados en campo (Tabla 6). Esto se puede deber a que los endmembers tomados de diferentes componentes de los cultivos de café sí muestran diferencias entre variedades de café y otros árboles asociados, así también con respecto a las hojas con presencia de roya, donde se observa un decaimiento de la reflectancia entre los 690 y 800nm (Figura 4).
De los diferentes árboles de decisión que se corrieron a partir de las imágenes de abundancia de los demezclados espectrales generados, se encontró que ninguno de ellos muestra exactitudes confiables, por lo que es necesario considerar otros endmembers que mejoren los resultados de las clasificaciones, ya que sí hubo una mejora en el método al utilizar endmembers tomados en campo (Tabla 6). Esto se puede deber a que los endmembers tomados de diferentes componentes de los cultivos de café sí muestran diferencias entre variedades de café y otros árboles asociados, así también con respecto a las hojas con presencia de roya, donde se observa un decaimiento de la reflectancia entre los 690 y 800nm (Figura 4).
El hecho de que las firmas espectrales muestren diferencias en el Red-Edge plantea la necesidad de probar los métodos antes mencionados en imágenes que tengan una resolución que contemple este rango del espectro electromagnético como es el caso del sensor RapidEye, la cual tiene una banda que va de los 690-730nm.
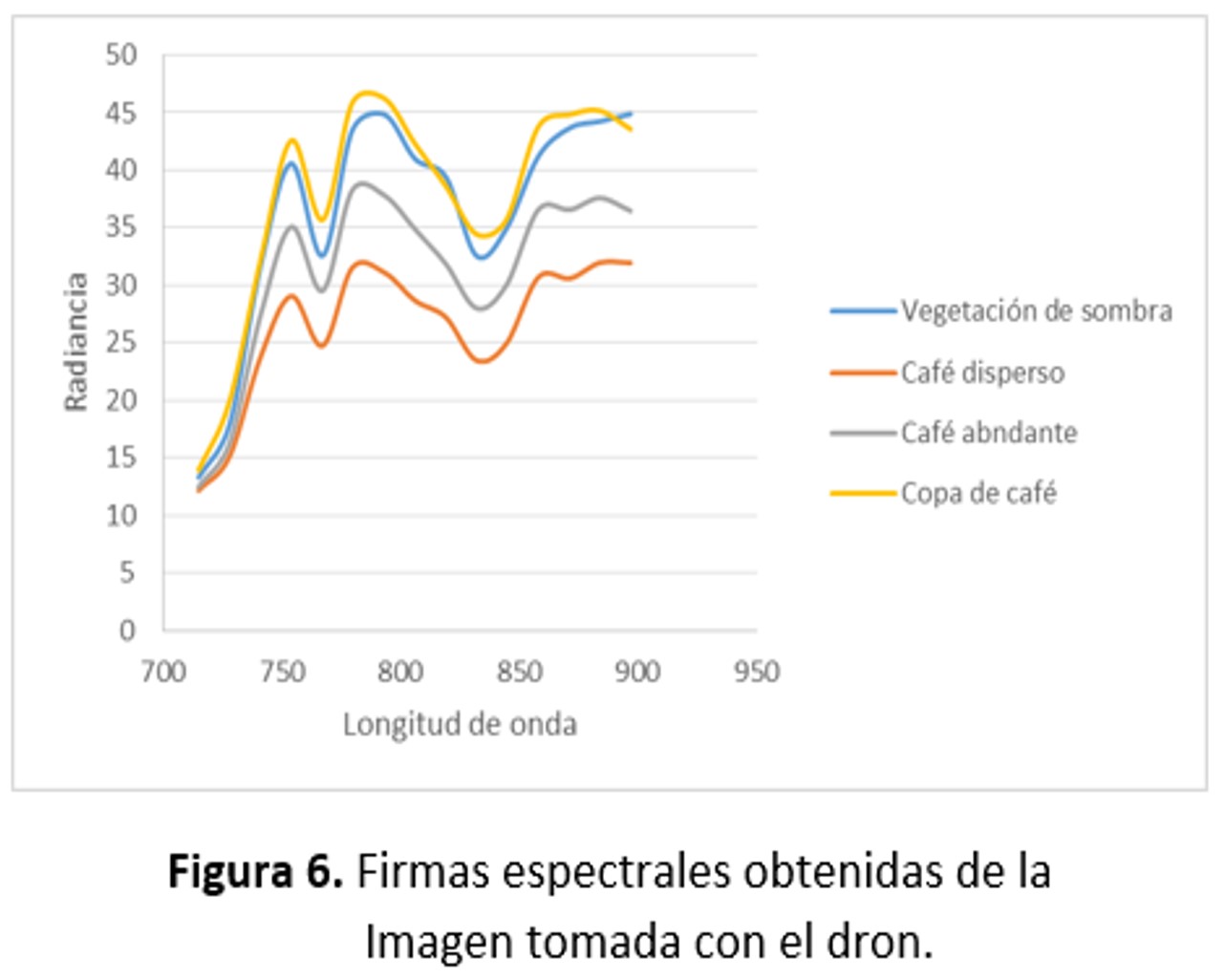
Por último, a pesar de que se consiguieron firmas espectrales sobre diferentes componentes del cultivo de café a nivel de hoja y en algunos casos a nivel de cobertura (con la pistola; Tabla 7) estas últimas se vieron afectadas por las condiciones de humedad relativa y la nubosidad, por lo que no pudieron usarse. Aunado a lo anterior está el hecho de que la imagen tomada por el dron se dañó en las bandas verde, roja y azul lo que hizo que no pudieran generarse firmas aéreas a partir de ésta y por lo tanto tampoco pudieron emplearse para llevar a cabo las clasificaciones propuestas, lo que derivó en exactitudes bajas. Aun así, en el rango del espectro que no se vio afectado, las firmas aéreas sí muestran diferencias entre la cobertura de café densa, dispersa y la vegetación asociada a la sombra del café (Figuras 5 y 6).


Hacia un monitoreo…
El presente trabajo muestra una primera aproximación a la identificación de café mediante diferentes métodos de percepción remota tanto supervisados paramétricos como no supervisados y no paramétricos. De todos ellos, el que mostró mejores resultados fue el clasificador de Máxima Verosimilitud, pero a pesar de esto, arroja una confiabilidad no mayor al 70% por lo que es necesario implementar mejoras, sobre todo en la toma de datos semillas para incrementar la confiabilidad de éste. Dentro de ellas se debe considerar aumentar los campos de entrenamiento y verificación, sobre todo los de café, ya que en este trabajo no se contó con un número suficiente de estos para lograr una confiabilidad mayor.
Con respecto a los árboles de decisión implementados a partir de las imágenes de abundancia de los diferentes tipos de demezclado espectral (lineal con Landsat 8 y derivado de los endmembers en campo), el que mostró mejores resultados fue el generado con los endmember obtenidos de campo, pero aun así, fueron bajos (alrededor del 10% de confiabilidad), por lo que es necesario incrementar la muestra de estos y sobre todo generarlos a nivel de dosel, ya que al utilizar los creados a partir de la hoja, el método muestra valores fuera de rango, lo que hace que las imágenes de abundancia creadas a partir de estos sean poco confiables para el análisis.
Los métodos mostrados en este estudio se implementaron en imágenes Landsat 8, cuyas resolución espacial y espectral pueden no ser las mejores para la identificación de café, por lo que es importante probarlos en imágenes de otros sensores como RapidEye, la cual tiene mejor resolución espacial (5m) y una banda que contempla el Red-Edge, región del espectro electromagnético en la cual las firmas espectrales de café y de otros elementos sí mostraron diferencias, tanto a nivel de hoja como a nivel del dosel, sobre todo a la presencia de la roya en el caso de la hoja.
Los endmembers a nivel de hoja se tomaron sólo para un sitio ubicado en la Sierra Madre de Chiapas cuya vegetación era bosque mesófilo y en condiciones de iluminación pobres pues la humedad relativa era de 100%, lo que provocó que los endmembers recolectados tuvieran ruido, sobre todo aquellos que se tomaron con la pistola, por lo que es necesario crear campañas de muestreo donde se pueda tomar un mayor número de muestras y en diferentes condiciones, así como en distintos ecosistemas, esto para alimentar modelos más robustos como los de transferencia radiativa.